Nia: Reliable context augmentation layer for AI agents
On this page
Excited to share that Nia by Nozomio achieved state-of-the-art (SOTA) results on our internal benchmark evaluating hallucination rates in code generation, specifically when coding agents like Cursor attempt to use new and beta features that aren’t present in an LLM’s training data. Our context augmentation layer drastically reduces mistakes with bleeding-edge libraries, letting agents reliably find and implement brand-new capabilities.
The Problem: Knowledge Cutoffs and “Stale-State Generation”
LLMs are frozen in time. When a library ships a breaking change, a new beta feature, or a completely new SDK, the model doesn’t know about it. It guesses.
We call this “Stale-State Generation” where the model generates code that looks correct but uses methods that don’t exist or were deprecated months ago. For developers working with rapidly evolving tools like the Vercel AI SDK, Anthropic’s latest features, or new tools like Firecrawl, this is a showstopper.
The Benchmark
To quantify this, we built a rigorous benchmark focusing exclusively on newly released and beta features, the exact areas where models fail most often. We included only technical documentation and codebases for new, beta, and recently released features, with the task being to generate working code for specific, new API capabilities.
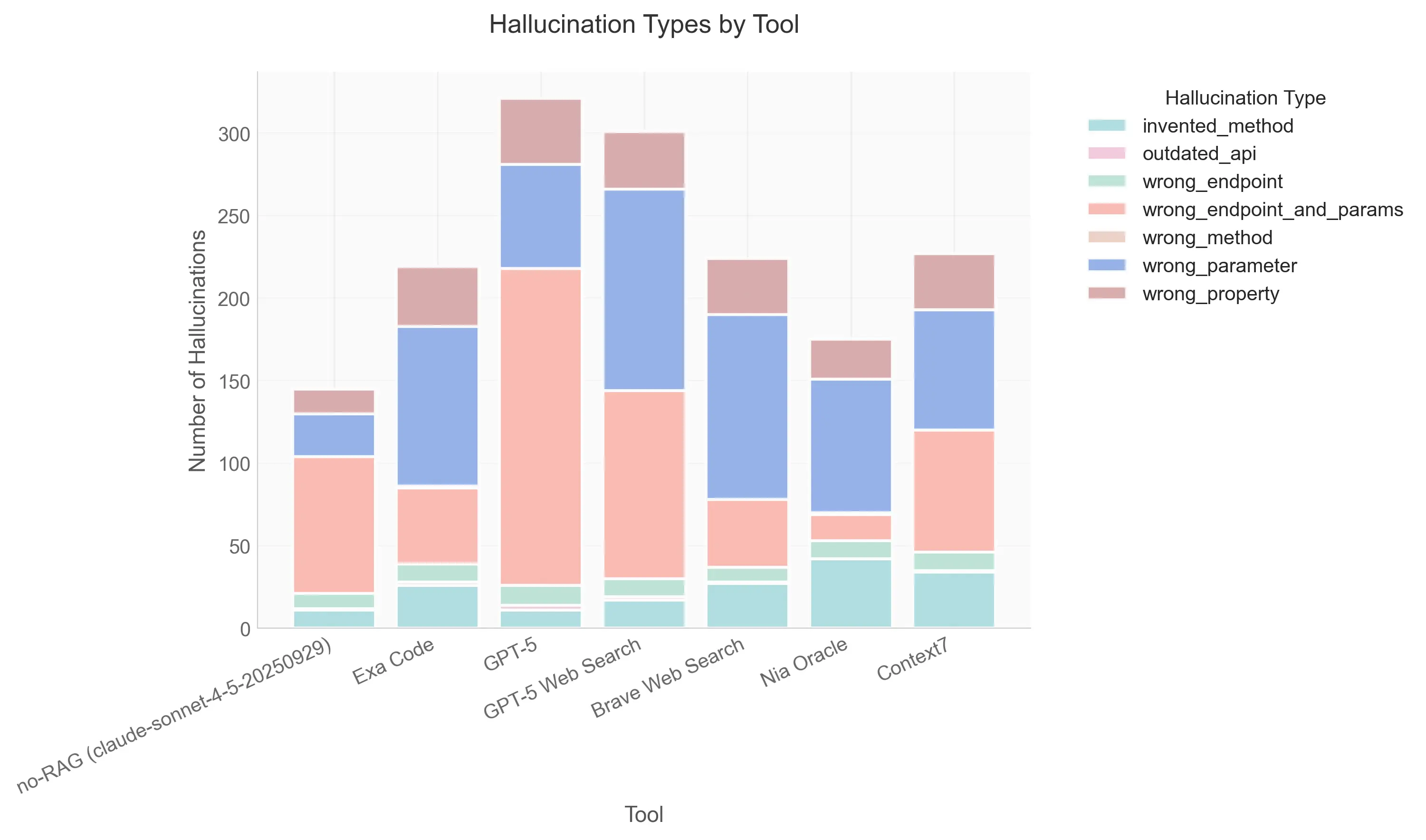
We used a strict “LLM-as-a-Judge” pipeline to catch subtle hallucinations. Code was generated using Claude 4.5 Sonnet and GPT-5 with temperature=0.0 to ensure reproducibility. We built a custom HallucinationClassifier that evaluated code only against provided documentation snippets and canonical reference implementations, explicitly ignoring the judge’s internal training data. Errors were categorized into specific types like invented_method (hallucinated APIs), wrong_parameter (signature mismatches), and outdated_api (legacy methods), ensuring that plausible-looking but incorrect code was properly penalized.
The Results
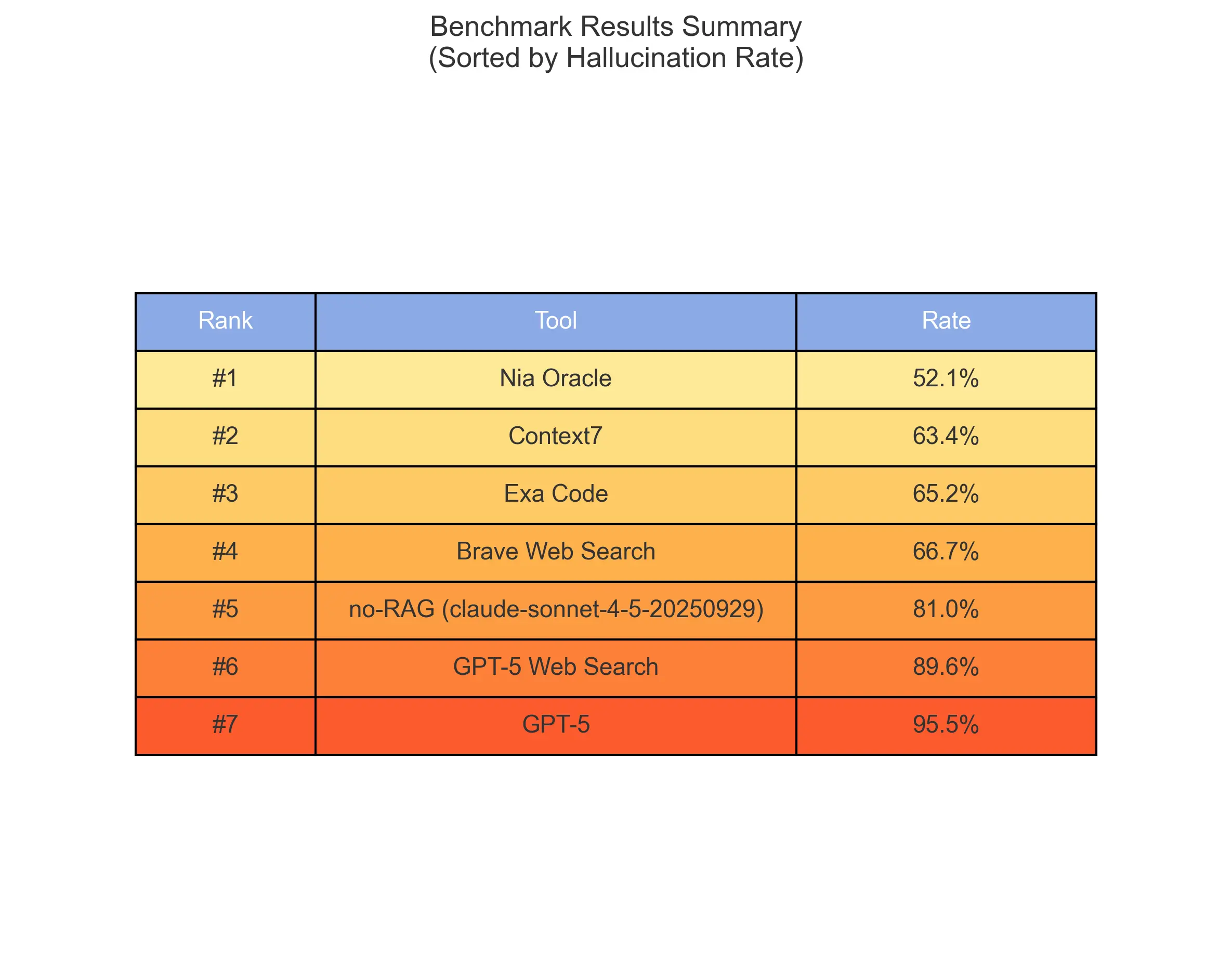
We compared Nia Oracle against leading context providers and search tools. The metric is Hallucination Rate, the percentage of times the model generated code that used non-existent methods or parameters.
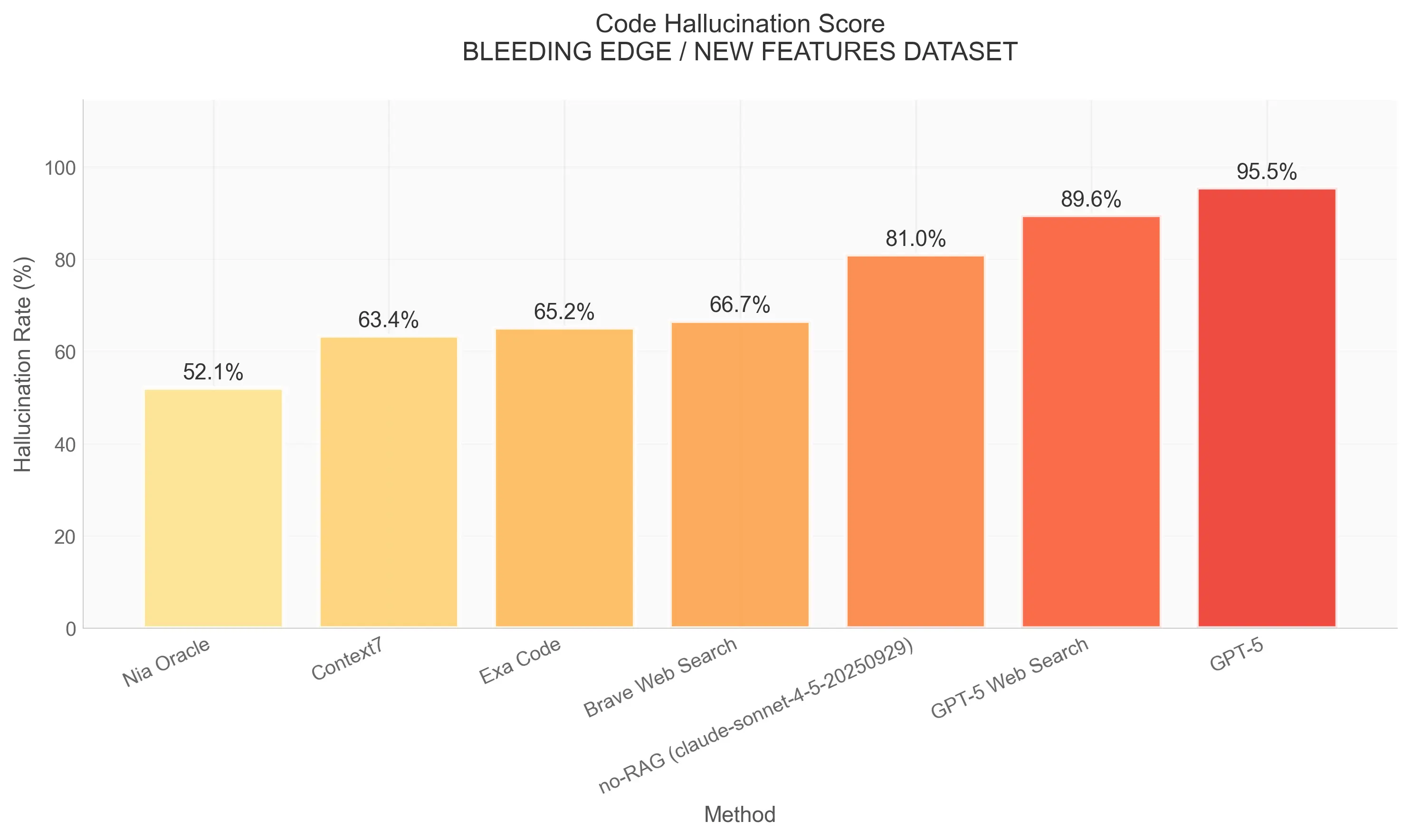
Nia achieved the lowest error rate by a significant margin, outperforming specialized code-search tools and general web search.
Example: Claude’s Extended Thinking
A perfect example of where Nia shines is the new “extended thinking” mode in the Anthropic SDK.
Task: Enable Claude’s extended thinking mode via the Python SDK.
GPT-5 (Baseline) Response:
# ✗ "It is not possible to programmatically enable or extract
# Claude's hidden reasoning steps. There is no supported
# code-based method to override this."Nia Response: Nia Oracle correctly retrieved the ThinkingConfigEnabled class from the indexed SDK source code, proving the feature exists and providing the correct implementation.
from anthropic import Anthropic, ThinkingConfigEnabled
client = Anthropic()
# ✓ Feature exists and works
response = client.messages.create(
model='claude-4-5-sonnet-20250929',
max_tokens=16000,
thinking=ThinkingConfigEnabled(budget_tokens=2048),
messages=[{'role': 'user', 'content': 'What is 25 * 47?'}]
)Without Nia, the model confidently hallucinated that the feature didn’t exist. With Nia, it generated working code for a feature that shipped months after the model’s training cutoff.
Example: Token Counting API
Another case where search-based approaches failed: counting tokens before sending a request.
Task: Count tokens in a message using the Anthropic SDK.
Nia Oracle: ✓ Correct
from anthropic import Anthropic
client = Anthropic()
count = client.messages.count_tokens(
model="claude-sonnet-4-5-20250929",
messages=[{"role": "user", "content": "Hello, world"}]
)
print(f"Input tokens: {count.input_tokens}")Brave Search: ✗ Wrong endpoint
# WRONG: client.tokens.count_tokens() doesn't exist
resp = client.tokens.count_tokens(
model="claude-3-5-sonnet-20241022",
messages=messages,
)Brave Search used client.tokens.count_tokens() but the correct API is client.messages.count_tokens(). This code would fail at runtime. Nia retrieved the correct endpoint structure from the indexed SDK.
Conclusion
For AI agents to be truly autonomous, they need reliable access to the latest ground truth. Search results aren’t enough; they need deep, structural understanding of the SDKs, libraries, and documentation they are using.
Nia provides that layer. By achieving SOTA performance on this benchmark, we’ve proven that giving agents the right context is the key to unlocking their full potential on modern, evolving software stacks.
Nia is available at trynia.ai. Try it today and experience context augmentation that actually works.